FastTrack’D Projects
SQL Projects
Python Projects
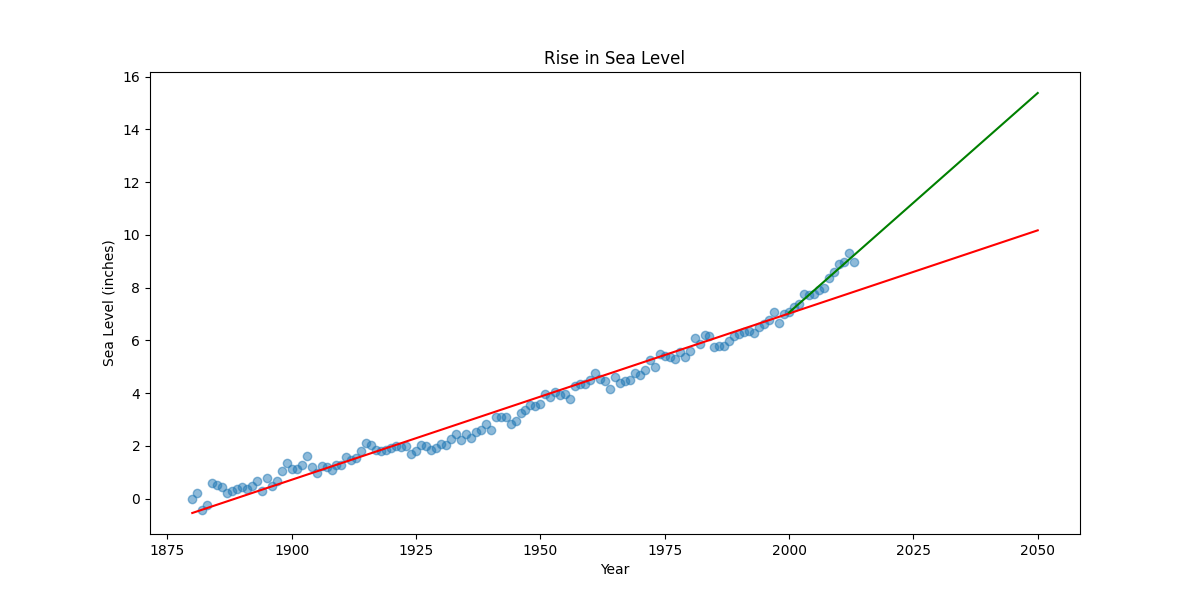
- Loaded and visualized historical sea level data from 1880 to 2013.
- Implemented linear regression to predict sea levels up to 2050.
- Created two lines of best fit: one for all data and one for data since 2000.
- Visualized predictions with scatter plots and regression lines.
Visualization(s)
# Example: Linear Regression for Sea Level Prediction
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import linregress
def draw_plot():
# Read data from file
df = pd.read_csv("epa-sea-level.csv")
print(df.head())
fig, ax = plt.subplots(figsize=(12,6))
ax.scatter(df["Year"], df["CSIRO Adjusted Sea Level"], label = "Original Data", alpha=0.5)
# Create first line of best fit and scatter plot
slope, intercept, r_value, p_value, std_err = linregress(df["Year"],df["CSIRO Adjusted Sea Level"])
x_vals = pd.Series(range(df['Year'].min(), 2051))
y_vals = slope *x_vals + intercept
ax.plot(x_vals, y_vals, 'r', label = f'Best Fit (1880-2050): y = {slope:.4f}x + {intercept:.2f}')
# Create second line of best fit
df_recent = df[df['Year'] >= 2000]
slope_recent, intercept_recent, r_value_recent, p_value_recent, std_err_recent = linregress(df_recent["Year"],df_recent["CSIRO Adjusted Sea Level"])
x_future = pd.Series(range(2000, 2051))
y_future = slope_recent * x_future + intercept_recent
ax.plot(x_future,y_future,'g', label = f'Best Fit (2000-2051): y = {slope_recent:.4f}x + {intercept_recent:.2f}')
# Add labels and title
plt.xlabel("Year")
plt.ylabel("Sea Level (inches)")
plt.title("Rise in Sea Level")
# Save plot and return data for testing (DO NOT MODIFY)
plt.savefig('sea_level_plot.png')
return plt.gca()
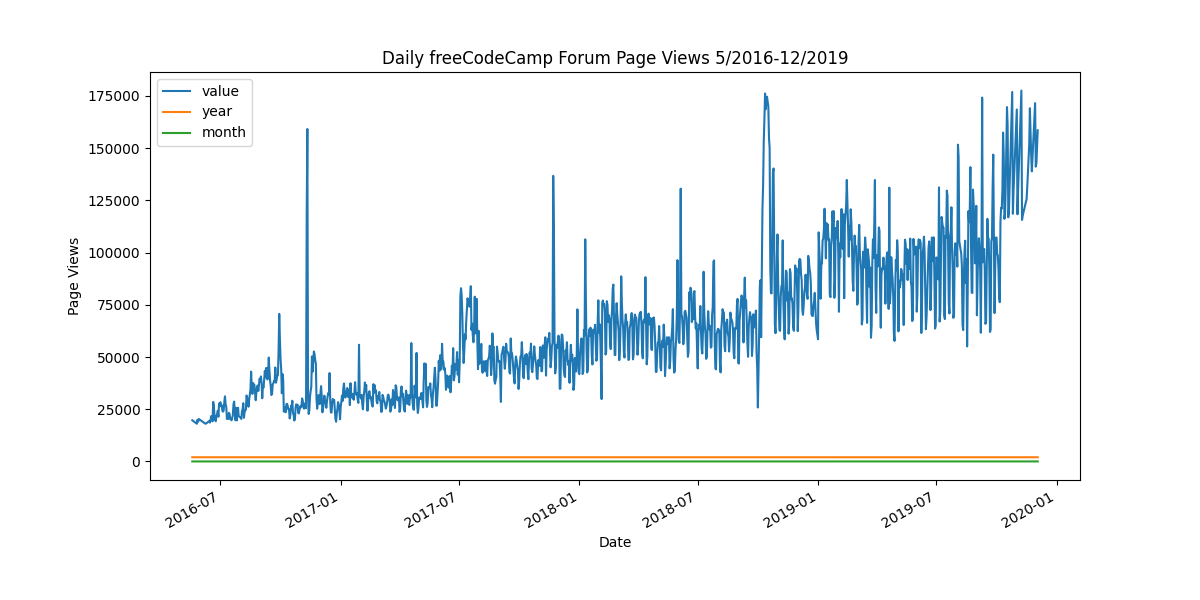
- Cleaned and filtered data to remove outliers.
- Created a line plot to show daily page views over time.
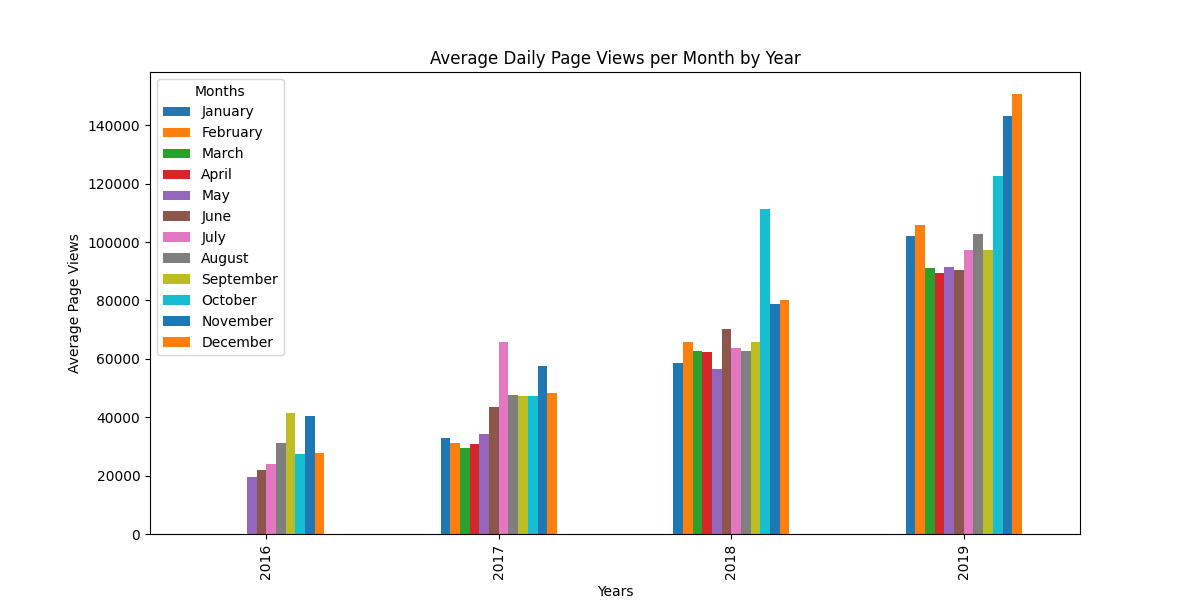
- Generated a bar plot to display monthly averages grouped by year.
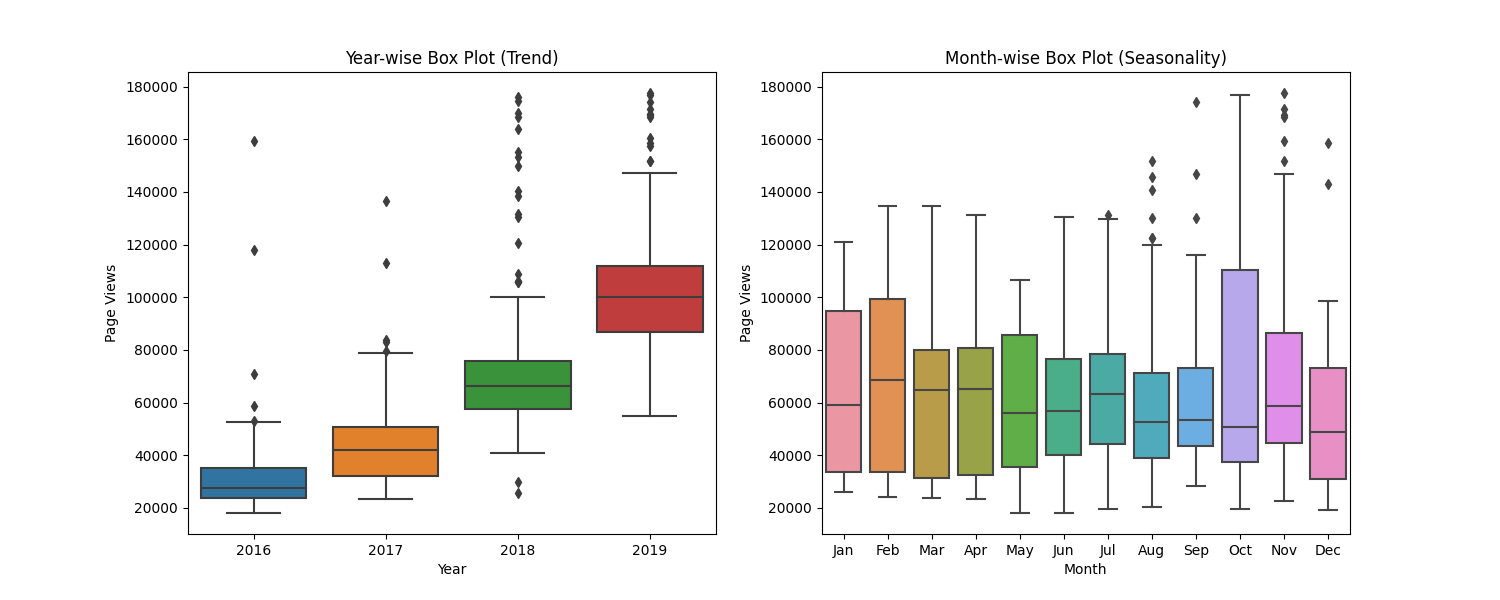
- Designed box plots to visualize yearly and monthly distributions.
Visualization(s)
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import numpy as np
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
if not hasattr(np, 'float'):
np.float = float
# Import data (Make sure to parse dates. Consider setting index column to 'date'.)
df = pd.read_csv("fcc-forum-pageviews.csv", parse_dates=["date"], index_col='date')
# Clean data
total_views = df['value'].sum()
df = df[
(df['value'] < df['value'].quantile(0.975)) &
(df['value'] > df['value'].quantile(0.025))
]
def draw_line_plot():
# Draw line plot
fig = df.plot(figsize=(12, 6), kind='line', title='Daily freeCodeCamp Forum Page Views 5/2016-12/2019', ylabel='Page Views', xlabel='Date').get_figure()
fig.savefig('line_plot.png')
return fig
def draw_bar_plot():
# Copy and modify data for monthly bar plot
df['year'] = df.index.year
df['month'] = df.index.month
# Group by year and month, and calculate the mean daily page views for each month
monthly_avg = df.groupby(['year', 'month'])['value'].mean().unstack()
# Plot the bar plot (each month as a separate series)
ax = monthly_avg.plot.bar(figsize=(12, 6), title='Average Daily Page Views per Month by Year', xlabel='Years', ylabel='Average Page Views')
# Add legend title and month names directly
months = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December']
ax.legend(title='Months', labels=months)
# Get the figure from the axes object and save the plot
fig = ax.get_figure()
fig.savefig('bar_plot.png')
return fig
def draw_box_plot():
# Prepare data for box plots
df_box = df.copy()
df_box.reset_index(inplace=True)
df_box['year'] = [d.year for d in df_box.date]
df_box['month'] = [d.strftime('%b') for d in df_box.date]
# Draw box plots
month_order = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
sns.boxplot(x='year', y='value', data=df_box, ax=axes[0])
axes[0].set_title('Year-wise Box Plot (Trend)')
axes[0].set_xlabel('Year')
axes[0].set_ylabel('Page Views')
sns.boxplot(x='month', y='value', data=df_box, order=month_order, ax=axes[1])
axes[1].set_title('Month-wise Box Plot (Seasonality)')
axes[1].set_xlabel('Month')
axes[1].set_ylabel('Page Views')
fig.savefig('box_plot.png')
return fig
- Calculated BMI to classify individuals as overweight.
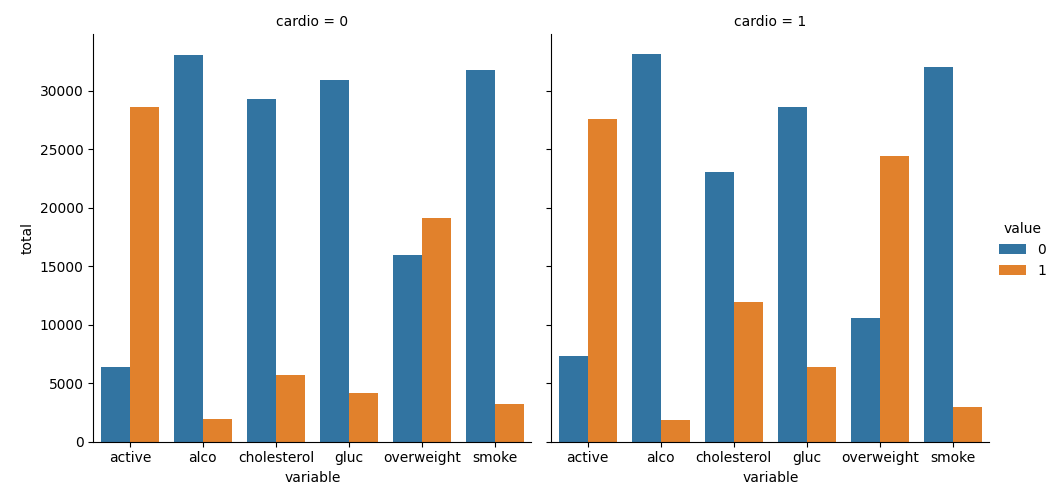
- Created categorical plots to compare health metrics by cardiovascular disease status.
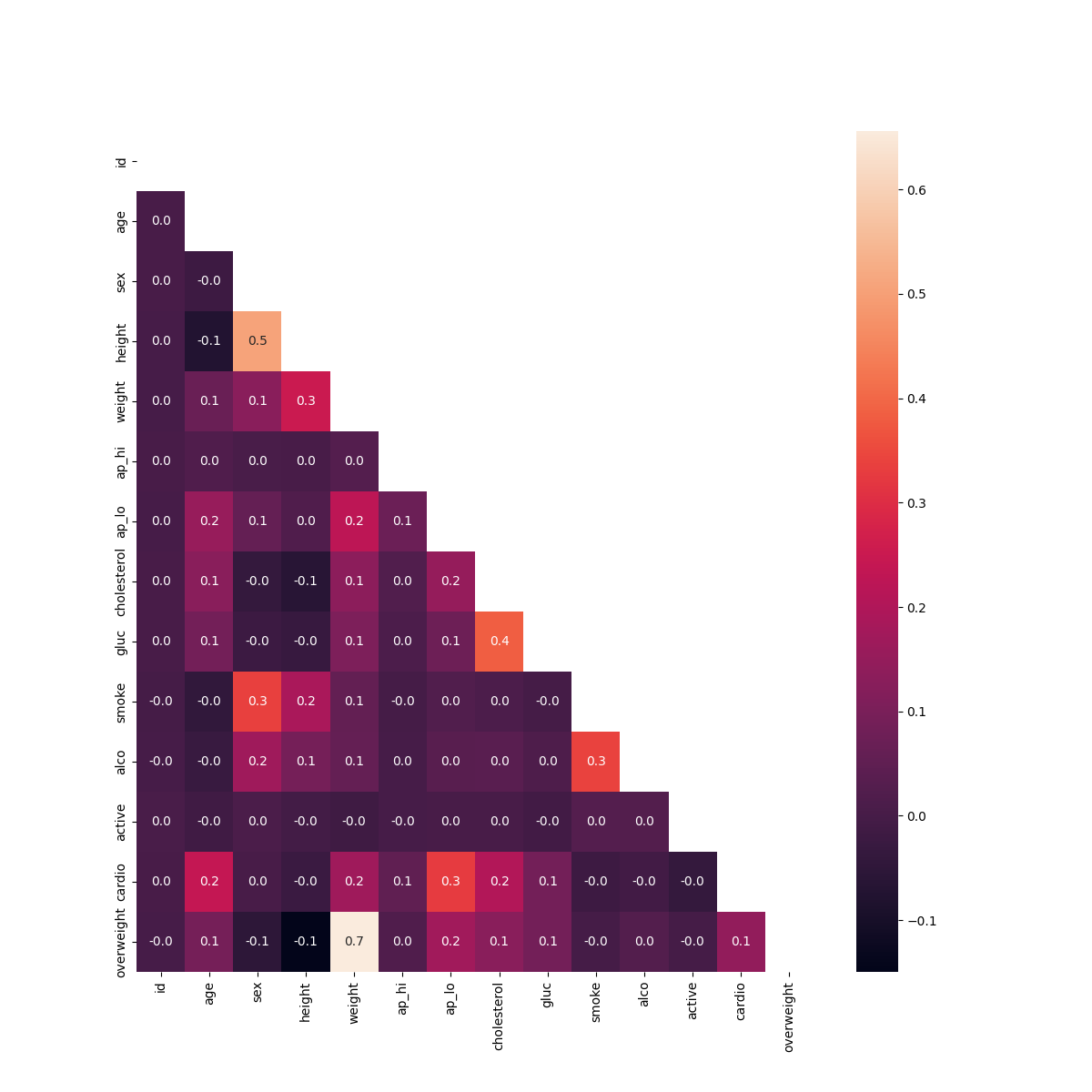
- Generated a heatmap to visualize correlations between health metrics.
- Cleaned data by removing outliers and invalid entries.
- Full script available for download!
Visualization(s)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("medical_examination.csv")
print(df.head())
df['overweight']=(df['weight'] / (df['height'] / 100) ** 2 > 25).astype(int)
df['cholesterol'] = (df['cholesterol'] > 1).astype(int)
df['gluc'] = (df['gluc'] > 1).astype(int)
print(df.head())
def draw_cat_plot():
# Create DataFrame for cat plot using `pd.melt` with specified variables
df_cat = pd.melt(df, id_vars=['cardio'],
value_vars=['cholesterol', 'gluc', 'smoke', 'alco', 'active', 'overweight'])
# Group and reformat the data to split it by 'cardio'
df_cat = df_cat.groupby(['cardio', 'variable', 'value']).size().reset_index(name='total')
# Draw the catplot
fig = sns.catplot(x='variable', y='total', hue='value', col='cardio',
data=df_cat, kind='bar').fig
# Do not modify
fig.savefig('catplot.png')
return fig
def draw_heat_map():
df_heat = df[
(df['ap_lo'] <= df['ap_hi'])&
(df['height'] >= df['height'].quantile(0.025))&
(df['height'] <= df['height'].quantile(0.975))&
(df['weight'] >= df['weight'].quantile(0.025))&
(df['weight'] <= df['weight'].quantile(0.975))
]
corr = df_heat.corr()
mask = np.triu(np.ones_like(corr, dtype=bool))
fig, ax = plt.subplots(figsize=(12, 12))
sns.heatmap(corr, mask=mask, annot=True, fmt=".1f", ax=ax)
fig.savefig('heatmap.png')
return fig
